We learned a great deal about Parsing algorithms in previous articles of this course. In one sentence, a Parser is a software that receives a list of Token objects and decide whether such a list fulfills the constraints given by a Formal Grammar.
In other words, within a Compiler, the Parser is the element that makes sure the grammatical rules are respected.
At the organization level, the Parser is the second step in front-end compilation, after Lexical Analysis, but before Semantic Analysis. As we’ve already discussed in depth, front-end compilation is the part of the Compiler that makes sure the source code is well written, both syntactically and semantically.
Often, the Lexer and Parser are implemented at the same time (in the same software module), in particular because many implementation patterns are the same for the two of them. Instead, I built them as two separate modules.
The reason is the same as the whole objective of this entire course: to practice and understand as many details as possible.
Thus, in this article I will tell you how I implemented a Parser for the Grammar described in the previous article. I will try to keep it self-contained, even though it goes without saying that you should also read the latter, to have a better understanding of this one.
The parser I built is a Top-Down, Leftmost, Recursive Descent Parser for a LL(1) Grammar. This means that the implementation uses recursive functions, and it does not use backtracking. The latter point comes thanks to the LL(1) property, and it’s definitely a nice thing to have.
Before to start, I want to clarify what is the input and what the output of the Parser module. This is also very useful to clarify the role of the Lexer.
Feed Input To The Parser
From a purely logical point of view, I recommend you to think about the Parser like a large module in your overall project. This project is called Compiler.
Like in any normal software architecture, a module expects some input. In the case of the Parser module, it’s expecting a list of Tokens as input. What’s that? Let’s take a look.
First of all, the list of Tokens is the output of the Lexical Analysis module. Strictly speaking, this is all you need to know about the Lexer. Let’s see what the list of tokens looks like, to better understand a few concepts.
A list of Tokens is a list of pairs, where each pair is of the form <lexeme, type>.
- The lexeme is a sequence of characters (the actual string contained in the Token).
- The type identifies the type of Token! For example, keyword, variable, number, etc.
Let’s take a look at some examples now. Suppose you want to produce a list of Tokens from the following input sentence
x = 3 * y;The Lexer should produce something very close to the following list:
<"x", Variable>,
<"=", Equal>,
<"3", Number>,
<"*", Operator>,
<"y", Variable>,
<";", Semicolon>.In fact, something very close to this example also happens in the Lexer that I wrote for my own Context Free Grammar. The actual result will be:
<"x", Var>,
<" ", Whitespace>,
<"=", Equal>,
<" ", Whitespace>,
<"3", Integer>,
<" ", Whitespace>,
<"*", Star>,
<" ", Whitespace>,
<"y", Var>,
<";\n", Endline>.Thanks to this simple example you should also get a decent understanding of how the Lexer works:
- It takes a source file,
- Reads character after character,
- Matches groups of consecutive characters with one of the Token Types that the designer (in this case me) specifies.
The Lexer can also raise an error, if it finds a character that is not allowed by the Alphabet, or if a sequence of character does not match any regular expression defined in the Grammar. In this case, the compilation ends with an error. Instead, if everything goes smoothly then it will return the list of Tokens it has built, which, once again, it’s fed as input to the Parser.
Even though the Lexer would probably deserve an entire article for itself, for the moment this is more than enough to understand the remainder of this article!
The only question remaining is how to actually implement the Token list?
I defined two structures to solve this problem. The first is meant to store information of a single Token, while the second is useful to link Tokens each to another in the right order.
struct Token{
char *lexeme;
enum TokenType type;
};TokenType is simply a Enum data structure, which is a basic data type in C. My definition is:
enum TokenType {
// Basic Token Types in the Grammar
Comma,
Lpar, // (
Rpar, // )
Lbrack, // [
// many more...
};Finally, the TokenList is just another struct, defined as
struct TokenList {
struct Token *token;
struct TokenList *next;
};This is a very common software design pattern, used to implement linked structures, such as LinkedList. I will discuss it more in detail in a second. For the moment, just fix in mind that the actual output of the Lexer is a pointer to a TokenList structure. In fact, my header file lexer.h exposes a function with this definition:
struct TokenList* build_TokenList (const char* fp);The first thing the Parser does is to call that function by passing the content of a File, and get in return a pointer to a TokenList struct.
Output of the Parser
I want to discuss with you the output of the Parser right now, before to start discussing its implementation. The reason is that the Parser has to produce a fairly complex data structure, and return it, therefore it’s important to ponder this choice at the beginning.
Formally speaking, the Parser must produce a Parse-Tree. This is the name conventionally assigned to a data structure, tree-like, that stores information about how Tokens are logically connected in the program. I discussed the Parse-Tree in a previous article, but I think here the easiest is to look at some examples.
Let’s consider the following source code:
z = x + y;Referring to the Grammar I designed, the Parse-Tree of this 1-liner code should look like the following:
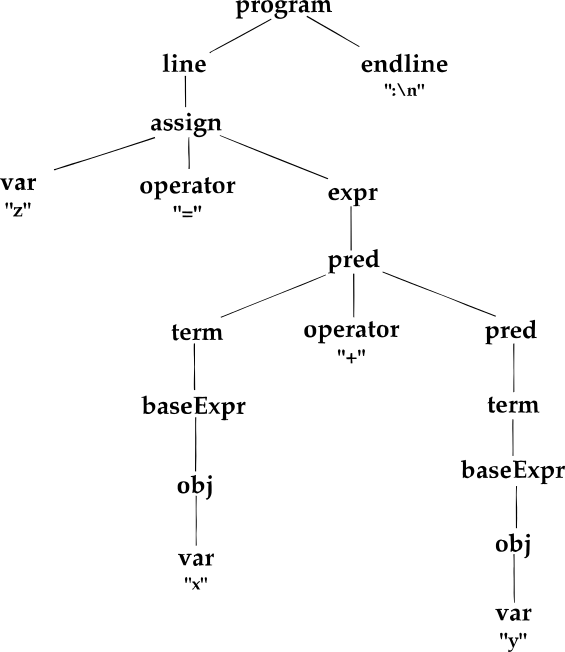
Quite a large stuff, for a 1-liner.
The point here is that the parse-tree must encapsulate the logic of the entire program. So, in order to correct parse an expression (Token expr), and to store it somehow in memory while still having understanding of operator priority, sub-expression, etc, we need the entire branch that starts with the Expr node.
On the other hand, the upper levels in the parse-tree are meant to store the logic of the entire program, which, in my Grammar, is a sequence of line, Endline Tokens.
A different, and more interesting question is - Is this the optimal way to store the parse-tree in memory?.
Brilliant question. The answer is definitely no, it’s not. In fact, there are plenty of optimization techniques that can be used at this point. Some are relatively easy to understand.
For example, an improvement could be to remove nodes that have just a child, like the line node is in the tree above. It could directly be replaced with the Assign node.
Other techniques are extremely complicated, and arguably even more powerful. I haven’t implemented nor studied them yet.
At any rate, I decided I want to build a full, thus redundant, parse-tree in my Parser. Why? Because my objective was to understand in depth the concepts. Premature optimization is usually source of troubles, mistakes and bugs in the code. Thus, I will first work on implementing a general Parser that produces a full parse-tree, and then work on optimization later.
With that decided, now the question is how to implement a data structure that allows to build (and navigate) a parse-tree. The first thing that comes to mind could be a structure like this
struct ParseTree {
struct Token *data;
struct ParseTree *left_child;
struct ParseTree *right_child;
};This idea is definitely based on a sound logic: to implement the parse-tree as a root node storing the “data” Token, along with two pointers to sub-trees.
In fact, this is a very common way to build binary trees in memory. Just store one value for each node, and two pointers that link the current node with its children.
Just to mention the easiest case where this logic is used, do you know how LinkedList are stored in Java (and other languages)? Pretty much in a similar way:
class LinkedList {
int data;
LinkedList resOfTheList;
// public and private methods to follow...
// ...
}The actual definition is more complex, because it also deals with generic, inheritance and whatnot. Things are a bit easier in Java as pointers to objects in the heap are not explicit. But I do want to do things explicitly, to learn the most I can, which is why I chose C as language to implement my design.
After this small digression, you should see a big problem in the data structure. I cannot know a-priori how many children a node in parse-tree has got! This makes very difficult, if not impossible, to define a data structure like the one for binary trees.
I solved this problem by redesigning the data structure. A small tweak, and a nice trick. Instead of storing two (or… infinite) children, I always store only one child, which will also have a pointer to its sibling!
struct ParseTree {
struct Token *data;
struct ParseTree *child;
struct ParseTree *sibling;
};If you should need a graphical visualization of this different representation, here it is! Compare it with the previous one, and highlight the differences.
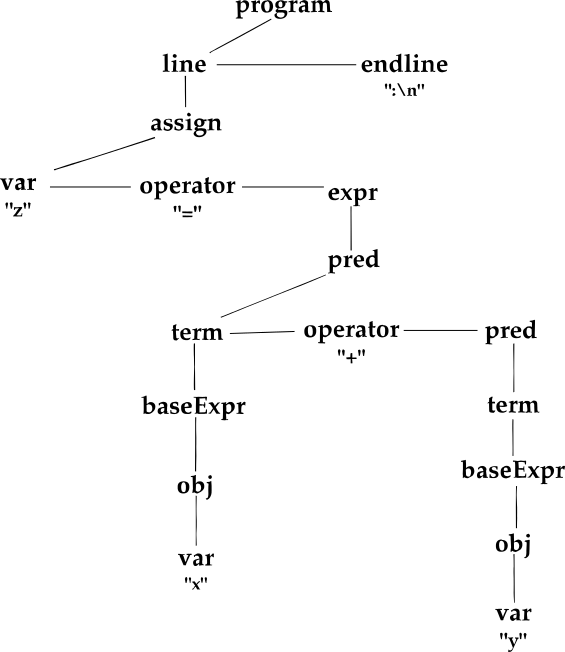
It should also be clear now why I introduced the example about LinkedList: when you think about it, the “sibling” pointer is very much like a “horizontal” LinkedList in the parse-tree. You can navigate such a list of siblings with a code like the following.
struct ParseTree *root = ... // current node;
while (root->sibling != NULL) {
root = root->sibling;
// do something useful with root...
}Alright! Now, with input and output clarified, let’s take a look at how the Parser is implemented, from a high-level point of view and in order to discuss some software implementation patterns and a bit of parsing theory.
Parser Implementation Overview
Instead of jumping straight into the writing of some complicated code, it’s worth spending some time planning ahead how the code should be organized.
In this sense, the header file of a C program is a good representation of the planning. Here’s what I will need:
- A set of global variables to identify if the Parser completed successfully, or what was the error otherwise.
- A function to allocate a new ParseTree into memory each time it’s needed. In modern languages this is not needed, but I chose to use C to have full control over the program, and have my hands on every detail.
- A function to print the entire ParseTree on the standard output (aka, the terminal). Always useful to print out complex data structures, both as exercise and as a debugging tool!
- A function to free the memory taken by the ParseTree, after we have done using it. Two “interface” functions, to create the ParseTree from a pointer to FILE (or string) and from a TokenList.
So, summing up, here is how my header file parser.h looks like.
#include "lexer.h"
// main data structure
struct ParseTree {
struct Token* data;
struct ParseTree* child;
struct ParseTree* sibling;
};
// Return values
#define PARSING_ERROR -1
#define SUBTREE_OK 0
#define MEMORY_ERROR 1
// Allocate memory for the ParseTree
struct ParseTree* alloc_ParseTree();
// Print the entire ParseTree at screen
void print_ParseTree(struct ParseTree* tree);
// Free memory
void free_ParseTree(struct ParseTree* tree);
// Build the ParseTree from a File or directly from a TokenList
int build_ParseTree (struct TokenList* head, struct ParseTree** tree);
int build_ParseTree_FromFile (const char *fileName, struct ParseTree **tree);In case you are thinking that the definitions of Token and TokenList are missing, well spotted: I had them into lexer.h. In fact, Token, TokenList and TokenType belong “logically” to the Lexical Analysis, in my opinion.
Let’s now look at the easier functions first, as they are good examples that improve the understanding of how the ParseTree data structure works. These functions are also useful to study a few standard software design patterns.
Allocate a New ParseTree
It’s easy to imagine that in many, many points during the Parsing operations we will need to create a new ParseTree (or rather, a new sub-ParseTree), save into it some information and then link it to the rest of the tree.
Therefore, it makes sense to write a generic function that allocates the memory for a new ParseTree. The Modularity development pattern is really the basic of good software development.
struct ParseTree* alloc_ParseTree() {
struct ParseTree* tree;
tree = malloc(sizeof(struct ParseTree));
if (tree == NULL)
return NULL;
tree->data = NULL;
tree->child = NULL;
tree->sibling = NULL;
return tree;
}I think this function is easy to understand, even if you are not familiar with memory management in C. Small digression here: I know modern languages are far more advanced, and they very nicely abstract problems such as memory management and allocation. In fact, I mainly use Python and R for my job! That said, my warm suggestion is to learn the concept at least once in your life and practice them with a challenging C project. That’s what I am doing, in fact!
In this case, the only thing you need to know is the function malloc and the operator sizeof, C.
The function malloc takes an integer value and finds a location in memory that is available to store that much of space, returning a pointer to such location. If it can’t find any space, then it returns NULL, and you are in real trouble. If you don’t have anymore space in your machine then it means you have some memory leak, and you must optimize your code.
The operator sizeof simply computes the size of the operand. So, it’s perfect to be used within the malloc function, as I did in the code above.
Lastly, it’s worth noting that I did explicitly add NULL pointers to the data, child and sibling of the just-created ParseTree. If you don’t do that then any call do tree->child will yield an error, at runtime.
Let me repeat the above sentence in different words. After I create the space in memory for a new ParseTree *tree, using malloc, the other pointers inside tree are not allocated yet. So, if I call tree->child, to access its child, I will get an error. And what’s worse, this error won’t be at compilation time, it will be at runtime (that’s how the GCC compiler for C works). This type of errors can be very messy to debug, but simply initializing the pointers to NULL solve the problem.
Free ParseTree Memory
Let’s take a look at how the memory previously allocated for a ParseTree can be freed.
It’s important to understand that when we “have” a ParseTree in the code, what we really have it’s just a pointer to its root node. We don’t have any information about how big is the entire tree in memory.
We should walk over the entire tree, from child to child, and from sibling to sibling to get that information. Luckily, this is a perfect place to use the Recursive Data Structure software pattern. Let’s take a look at how I solved this problem.
void free_ParseTree(struct ParseTree *tree) {
struct ParseTree *sibling, *child;
sibling = tree->sibling;
child = tree->child;
free_Token(tree->data);
free(tree);
if (sibling != NULL)
free_ParseTree(sibling);
if (child != NULL)
free_ParseTree(child);
}First of all, the function free_Token(struct Token *tok) that I use within free_ParseTree, was defined in lexer.h and it just frees the memory for a Token data structure.
Now, let’s understand what free_ParseTree does.
- Get and save pointers to the child and the sibling of the current node.
- Free memory occupied by the Token inside the current node (the
tree->data). - Also free the memory occupied by the actual pointer
*tree. This is done with the C functionfree. - Now the tree is totally freed, but luckily we saved the pointers to its child and sibling. So, for the two of them, if the are not
NULL, we should simply do the same procedure. “Do the same”, in computer languages, means to call the same function recursively.
I really recommend fixing in mind this development pattern, because it’s extremely common with tree-like data structures.
Print a ParseTree at Screen
To print an entire ParseTree in a readable form at screen is somewhat tricky. The first question is, how do I want it to look like?
I was looking for something simple, but also very clear. Something that would let me understand the tree structure at a glance.
I decided for an output like the following:
<Program>
<Line>
<Assign>
<"x", Var>
<"=", Equal>
<Expr>
// more nested nodes ...
<Endline>
<Line>
<IfLine>
<"if", If>
<IfCond>
<Expr>
// nested nodes....
<IfBody>
// ...
<Endline>This way, the indentation on the screen of each node will tell how deep is that node in the tree.
Clearly, the indentation level must be a parameter. On the other, for the first level (the Program node) the indentation is always zero. So, I made the interface function print_ParseTree such that it just calls an internal function with the initial indentation.
void print_ParseTree(struct ParseTree *tree) {
print_PT(tree, 0);
}Like that, I can always call print_ParseTree with only one argument. Now, let’s see what the internal function print_PT does.
void print_PT(struct ParseTree* tree, int indent) {
if (tree == NULL)
return;
// This is a Depth-First print
if (indent > 0) {
char space[indent + 1];
memset(space, ' ', indent * sizeof(char));
memset(space+indent, '\0', sizeof(char));
printf("%s", space);
}
print_Token(tree->data);
struct ParseTree *sibling, *child;
sibling = tree->sibling;
child = tree->child;
print_PT(child, indent + 2);
print_PT(sibling, indent);
}This function is made by two parts. One is interesting from an algorithmic point of view, the other is interesting because it deals with string objects in C!
First of all, if the function is invoked with a NULL tree, then it simply returns. This case is less silly than you may think, because it’s the basic case of the recursion. Let me explain better.
As we will see, the function uses the recursive pattern too, therefore it will be called initially with the root of the ParseTree, and then many times with children and siblings. Therefore, checking if tree==NULL it’s necessary in order to check whether we arrived at the bottom of the tree (a leaf node).
Thus, basically, you should really think of the function print_PT as if it can be called anywhere in the middle of the ParseTree, and not just with the root node.
Now, let’s look at the reminder of the function.
- To start, something must be done if the indentation level is greater than zero. In fact, it will be zero only in one case, for the root. If it’s not zero then I must print some space before printing the current node.
- Printing N spaces in C (whatever integer N is), is not that straightforward. So, I first create a char array of indent+1 cells.
- I set the first N = indent cells to a whitespace
' ' - I set the
indent+1cell to'\0'. This is the special character in C that terminates string. If you forget it then the standard functionprintfwon’t know where to stop printing! To do these two operations I use the memset standard C function (aka, memory-set). - Call
printfto display the char array with all whitespaces.
- Now, regardless of whether some white spaces was printed out or not, print the data of the current node. This data is just a Token object, so I use the
print_Tokenfunction defined in lexer.h. - Finally, get pointers to child and sibling of the current node and call the same function recursively. Careful though! For the child, the function must be called with one more level of indentation.
It should be very evident that the print_PT function uses the same recursive logic that we previously saw in free_ParseTree. Only, in this case the indentation level must be handled as a parameter, and increased in some of the nested recursive call.
I believe that a final note about my comment in the code “This is a Depth-First print” is due, now.
What is Depth-First? It’s a name commonly used to identify a set of algorithms. The most common case is the Depth-First Search in a tree. Basically, if you want to know whether a given integer is stored somewhere in a tree of integers, you can start from the root node, then go as deep as you can in one branch and see if you find it. If not, get up one level, switch branch, and again go as deep as you can.
This way, in the worst case, you will have “visited” the entire tree and can tell for sure whether the integer was therein or not. Depth-First just means that you first go deep, then expand the search.
If you like eating pizza, think of Depth-Search as the most normal way to eat it: cut it into slices and eat each slice entirely, before going to the next slice.
The most common alternative to this algorithm is the Breadth-First Search. Thinking again about the search in a tree, with Breadth-First you start at the root and, as the first thing, you make sure that none of its children contains the integer. Then, for each of those children, you check their children. And so on.
What about the pizza? Imagine cutting the pizza in concentric circles, and eating each circle entirely, before passing on to the next concentric circle.
To print a ParseTree, the Breadth-First approach would make little sense, and it will just produce a messy visualization. That’s why I used Depth-First.
Parsing Subtrees
I explained the general concept of a Recursive Descent Parser in great detail in a previous article, thus, here I will focus on the main concepts and how to implement them.
The overall idea is not too difficult. The Parser looks at the TokenList and “consumes” one Token at time. For each new Token that it gets, it must choose what production rule in the Grammar corresponds to that Token, if any.
Just in case you forgot, a “production rule” is a syntactic rule in the Grammar, such as
assign : var '=' exprThus, every time a new Token is popped from the TokenList, the Parser must understand what rule in the Grammar must be used.
Now, the Grammar I designed is LL(1) (see previous article), which means the Parser just needs to look ahead one more Token in the TokenList to understand what’s the right production rule.
For example, let’s assume the current node under examination is a baseExpr Token. In this case, the Parser will look ahead to the next Token. If it’s an open parenthesis then it will choose the production rule
baseExpr : '(' expr ')'otherwise it will choose the rule
baseExpr : objas these two are the only possibilities the Grammar allows. If neither is successful, then the Parser must return a PARSING_ERROR.
The baseExpr Token is not the simplest of the subtree to parse. Nonetheless, I think it’s a good example to study and understand various concepts. So, let’s do it!
Here is, in words, how the baseExpr subtree must be parsed:
- First of all, make some space in memory and allocate a new node that will be the root of the new subtree.
- Now, look ahead at the next token. Let’s assume it’s an Lpar
'('Token.- Create a new node that will contain the
LparToken. - Use a general function that checks if the current token is really what we assume it is. This will return either
SUBTREE_OKorPARSING_ERROR. - If it returned
PARSING_ERRORthen propagate this error (in other words, stop). - If if was
SUBTREE_OKthen assign this current node (theLparnode) as a child of the node created at step 1. - Now, according to the Grammar there must be an
exprToken. This is the only possibility allowed. - So, make space in memory for an
exprnode, that will be the root of a new subtree. - Use a separate function to check that the next few Tokens in the TokenList really form an
exprToken. This will return eitherSUBTREE_OKorPARSING_ERROR. - If it returned
PARSING_ERRORthen propagate this error (in other words, stop). - If it was
SUBTREE_OKthen assign the node created at step 2.6 as sibling of theLparcreated at step 2.1. Why? Because the Grammar says so:baseExpr : '(' expr ')' - Now, according to the Grammar there must be a
RparToken, that is a closed parenthesis. Again, this is the only possibility. - So, create space in memory for a
Rparnode and call the same function used at step 2.2. - If the result is
SUBTREE_OKthen assign the node created at step 2.11 as sibling of theexprnode created at step 2.6. If instead it wasPARSING_ERROR, then stop and propagate this error.
- Create a new node that will contain the
- If instead the Token wasn’t an
Lpar, then it must be aobjToken. That’s the only possibility allowed by the Grammar.- Allocate in memory a new
objnode that will contain the subtree. - Use a separate function that gets the TokenList and checks whether the next few Tokens form a
objToken or not. This will return eitherSUBTREE_OKorPARSING_ERROR. - If the result was
PARSING_ERRORthen stop and return this error value. - If it was
SUBTREE_OKthen assign the node created at step 3.1 as child of the root node for thebaseExprcreated at step 1.
- Allocate in memory a new
I understand that the example is quite involved, but it does clarify many things. Let’s review them together.
First of all, it becomes clear that for each TokenType is useful to have a function that checks if the top of the TokenList really contains such Token.
I called these functions with the standard names is_<TokenType>. So, I have a function called is_BaseExpr that implement the example above, another is_Expr that checks for a generic expr, and even a function is_Program, that basically is the entry point of the Parser, and it’s also used for the body of the LoopLine, which is defined as loopLine : 'while' ifCond loopBody, and loopBody : program.
A very important detail is that each such function is_<TokenType> is responsible to advance the current head of the TokenList. For example, let’s assume I call the function is_Endline, that simply checks whether the next token in the TokenList is an Endline Token. If the function returns SUBTREE_OK, then, after the execution is finished, the head of the TokenList must not be anymore that Endline Token. We say that the Token has been consumed. For once, this is quite easy to do with in C, by using… double pointers!
The advantage of having all these functions is twofold. First of all, the software is much better designed when it’s split into small logical pieces. It helps to maintain the software, improve and test it in future releases.
In second place, you may notice that production rules are used one into another many times. For example, the program token is used as entry point but also as loopBody. The ifCond token is used both in ifLine and loopLine. The expr and obj tokens are used everywhere! In addition, the expr token can be nested recursively into another expr Token, under the path Expr, Pred, Term, baseExpr, ‘(’ Expr ‘)’.
So, all in all, it’s very useful to have separate functions that can be called one into another (or into themselves recursively), exactly as tokens are used into the Grammar definitions.
If at this point you are slightly confused then don’t worry. I am going to clarify many details in the next section, and then provide you with the entire code repository (see the references at the end).
What do we know so far?
Let’s briefly recap the previous sections, as they were quite dense of concepts. Here’s a list of the main concepts to fix in mind.
- To “navigate” a parse-tree, like to search an element into it, or to print it out at screen, we should use recursive functions, that is, functions that are called over a root node and internally call themselves over child and sibling nodes of that root.
- The Parser is a software organized in a very modular scheme. That is, a large collection of independent functions, which call each to another in many cases. This software design pattern improves sustainability of the Parser, testing and future additions.
- More about these many functions the Parser is split into. They strictly follow the definition in the Grammar. So if you have a rule in the Grammar such as
A : X Y, then you’ll have three functions in the Parser,is_A(...),is_X(...),is_Y(...). Just so that you know, in some books these standard functions may be calledmatch_A,match_X,match_Y. - The way these functions interact with each other (that is, invoke each other) also strictly follows the definitions in the Grammar. So, using the previous example
A : X Y, the functionis_Awill first create space in memory for a subtree of typeA, then will call the functionis_Xand finally the functionis_Y.
That should be enough for a review of the key points so far. Before going further with more technical details though, I really want to underline again the scientific perspective of this whole development.
The point I am trying to make is that, in the entire process, I have been following a clear methodology, the one I am now illustrating to you. This is scientific method. I absolutely did not jump straight into writing some dubious thousands lines of code, with poor results. I took my time to study parsing theory, and am sharing this knowledge with you.
Breaking It Down Into Pieces
In this final section of the article I am going to give more technical details, and then leave you with the references that include the code repository for the whole project.
To illustrate the concepts, I want to take a bottom-up approach this time. At the very bottom of the Parser we have the task to verify single TokenType and to advance the head of the TokenList.
This is a task that all functions is_<TokenType> will have to perform at least once. The more complex, such as is_Expr, will actually have to do it many times.
Hence, it makes perfect sense to write a function that takes care of this logical step. Let’s write it once for all, and then use it multiple times. I called it _single_Token_template, because it’s the common template function to verify a single Token!
int _single_Token_template(struct TokenList **tok, struct ParseTree **new, enum TokenType type, char *lexeme) {
if (*tok == NULL)
return PARSING_ERROR;
struct TokenList *current = *tok;
if (current->token->type != type) {
printf("Expecting <%s>, Found <%s>\n", type2char(type), type2char(current->token->type));
return PARSING_ERROR;
}
if (lexeme != NULL)
if(strcmp(current->token->lexeme, lexeme) != 0) {
printf("Expecting %s, Found %s\n", lexeme, current->token->lexeme);
return PARSING_ERROR;
}
struct Token* newTok = new_Token(current->token->lexeme, current->token->type);
if (newTok == NULL)
return MEMORY_ERROR;
(*new)->data = newTok;
(*new)->child = NULL;
(*new)->sibling = NULL;
*tok = current->next; // advance head of TokenList
return SUBTREE_OK;
}Now, let’s break this function into pieces and discuss each of them.
First of all the signature of the function. Clearly, it returns an integer, and this will be one of the globally defined return values (PARSING_ERROR, MEMORY_ERROR, SUBTREE_OK).
What about the input arguments? The first argument is a pointer to a pointer to a TokenList. If you are not used to write C code, this will seem very strange, but in fact it’s a very common case.
The key point is that function arguments are always passed by value in C, never by reference. This holds true for pointers too, and it’s quite different from what happens in Java or Python, when passing a complex object as argument means to give the reference to that object.
In C, everything is copied into the scope of the function. And you know perfectly well what’s a scope, because you studied this course! Therefore the only way to modify an object is to pass a pointer to it. And if that object is a pointer, then one needs to pass a pointer to a pointer… that’s a double pointer.
Also, remember that we do want to modify the TokenList, because we must advance its head to the next token. So, everything hopefully makes sense now.
The second argument is a double pointer to a ParseTree. The same logic applies here too. We want to modify this input argument, for example setting its internal data, child and sibling. Thus, we need a double pointer.
The third and fourth argument are simply the TokenType and the string (character array) that must match with the current head of the list, or an error will be returned.
Now, let’s look at the function body, and walk through it.
First, a sanity check. If the head of the list is NULL then this definitely doesn’t match the TokenType in input, so I return a PARSING_ERROR.
Then, I check if the type of the Token at the head of the TokenList is equal to the TokenType in input. If it’s not then I return a PARSING_ERROR. If it is, the function goes onto the next step.
Now I check whether the lexeme of the Token at the head of the list is equal to the lexeme in input. But I do so only if the latter is not NULL. Why is that? This helps because in case I want to invoke this function only to check the TokenType, I can do that giving NULL as last input. The useful analogy to think about in this case is with Python’s optional arguments.
If all of the previous checks passed, then I create space in memory for a new Token (the function new_Token was defined in lexer.h). I want to create an actual new Token, and not link the head of the TokenList, because I don’t know what that list will be doing in the future.
Let me clarify the last sentence. When I write a function that is supposed to be used by other modules/functions, I want to make sure that the behavior of it doesn’t depend on assumptions about what the called will do. In this case, if I linked the head of the TokenList as the new Token (instead of creating a new one in memory), and then the TokenList is modified of erased by some other piece of code… everything would fall apart!
This is an important concept in fact. Write robust functions, that depend the least possible on future behavior of the caller, and of the arguments they receive.
With that clarified, let’s see what happens next. Quite simply, the new Token is assigned as “data” of the subtree. Also, child and sibling are assigned to NULL, to prevent strange errors as I explained above.
Then, and this is the key moment, before returning a value and exiting the function, the head of the list is advanced. It’s worth noting that the function will arrive at this point only when all previous checks were OK.
So, now the question is why is this function useful? Let’s see: assume that at some point the Parser is dealing with an Assign Token, and needs to verify if the current Token (the head of the TokenList) is a var type. For that, as I explained to you, there will be a function is_Var(...). What’s this function?
int is_Var (struct TokenList **tok, struct ParseTree **new) {
return _single_Token_template(tok, new, Var, NULL);
}Quite easy, isn’t it? The function simply calls the template function with the correct arguments.
Do you need to implement the is_Plus(...) function, to check if the current Token is a plus Operator? Just write:
int is_Plus (struct TokenList **tok, struct ParseTree **new) {
return _single_Token_template(tok, new, Plus, NULL);
}Do you want to verify if the current Token is the continue keyword?
int is_Continue (struct TokenList **tok, struct ParseTree **new) {
return _single_Token_template(tok, new, Continue, "continue");
}Nice and fast! Notice that in the last case I also use the fourth input argument.
I was able to use the template function with almost all basic types, Minus, Div, Lpar, Lbrack, Var, Int, etc. This greatly reduced the amount of code I had to write, and definitely helped keeping things under control.
Obviously, not all is_<TokenType> function can be done in one line. So, let’s take back the is_BaseExpr example that we studied in the previous section and see how it’s implemented.
Remember, all is_BaseExpr(...) has to do is to make space in memory for the new Token/ParseTree, and then call the other functions as clarified by the production rule
baseExpr : obj | '(' expr ')'Here’s the whole function.
int is_BaseExpr (struct TokenList **tok, struct ParseTree **new) {
int status;
struct ParseTree *lpar, *rpar, *subexpr, *obj;
struct Token *newTok;
status = SUBTREE_OK;
newTok = new_Token((char[1]){'\0'}, BaseExpr);
if (newTok == NULL)
return MEMORY_ERROR;
(*new)->data = newTok;
if ((*tok)->token->type == Lpar) {
// is a sub expression
lpar = alloc_ParseTree();
if (lpar == NULL)
return MEMORY_ERROR;
status = is_Lpar(tok, &lpar);
if (status != SUBTREE_OK){
free_ParseTree(lpar);
return status;
}
(*new)->child = lpar;
subexpr = alloc_ParseTree();
if (subexpr == NULL)
return MEMORY_ERROR;
status = is_Expr(tok, &subexpr);
if (status != SUBTREE_OK){
free_ParseTree(subexpr);
return status;
}
lpar->sibling = subexpr;
rpar = alloc_ParseTree();
if (rpar == NULL)
return MEMORY_ERROR;
status = is_Rpar(tok, &rpar);
if (status != SUBTREE_OK){
free_ParseTree(rpar);
return status;
}
subexpr->sibling = rpar;
}
else {
// just a Obj
obj = alloc_ParseTree();
if (obj == NULL)
return MEMORY_ERROR;
status = is_Obj(tok, &obj);
if (status != SUBTREE_OK) {
free_ParseTree(obj);
return status;
}
(*new)->child = obj;
}
return status;
}If you (slowly) go through the code you will see that this function simply translates into C code the logic I expressed in words in a previous section, “Parsing Subtrees”. Enjoy the exercise!
Testing The Parser
No software project is well done without a battery of tests. I didn’t follow the so-called Test Driven Development methodology, in this case, although I often do in my projects. Nonetheless, I really wanted to create a set of unit tests for the Parser.
Now, testing my Parser was a tricky affair. Made even trickier by the lack of a standard library for unit testing in C. There are some libraries out there, but the only thing in the standard C is the assert module, with its assert.h header file. This file, basically, defines a function assert(...) that check whether its input is logically true.
So, using this very basic tool I created about 15 unit tests. Not a lot, I agree, but still something.
How do such tests work? Once again (and hopefully a nice conclusion to this article) I took an explicit approach:
- Each test defines its own input source code, that must be parsed.
- It calls the
build_ParseTreefunction from parser.h and gets the resulting status (integer). - It checks whether the status is as expected (can be
SUBTREE_OKwhen the input source code is alright, but can also bePARSING_ERRORwhen I purposefully introduce a syntax mistake in the source code for a test). - Then, if the parsing went fine, it walks through the ParseTree and explicitly checks if nodes and subtrees are as expected in the tree.
Let’s take a look at one example. I created a file, named it test_code_1 and wrote the following line in it:
readInt x;This is a 1-liner source code that should be well parsed. Then, I created a C program in a file called test_1.c and placed the following code into it.
#include <assert.h>
#include <stdio.h>
#include "../parser.h"
// gcc test_1.c ../parser.c ../lexer.c -o test_1.out
int main() {
struct ParseTree *tree, *walk;
int status;
char const* const fileName = "./test_code_1";
tree = alloc_ParseTree();
if (tree == NULL)
return MEMORY_ERROR;
// build the Parse Tree
status = build_ParseTree_FromFile(fileName, &tree);
// check if the result is as expected
assert(status == SUBTREE_OK);
// Now explicitly walk through the tree and check many stuff
walk = tree;
assert(walk->data->type == Program);
assert(walk->sibling == NULL);
walk = walk->child;
assert(walk->data->type == Line);
assert(walk->sibling->data->type == Endline);
assert(walk->sibling->child == NULL);
assert(walk->sibling->sibling == NULL);
walk = walk->child;
assert(walk->data->type == Input);
assert(walk->sibling == NULL);
walk = walk->child;
assert(walk->data->type == ReadIn);
assert(walk->child == NULL);
walk = walk->sibling;
assert(walk->data->type == Var);
assert(walk->sibling == NULL);
assert(walk->child == NULL);
printf("---------------\n");
printf("--- TEST OK ---\n");
printf("---------------\n");
free_ParseTree(tree);
return status;
}Following a similar logic, I created more tests, each with its own source code, and tested many things, found many bugs and solved all of them. The next bug is always waiting to be found, so if you spot it while looking at my code, please let me know!
Summary and Outlook
In this article we studied how to implement a recursive descent parser.
For once, the coding examples are real! They are part of the code that I wrote to implement the Parsing module in the Compiler I wrote for the programming language I created from the ground.
To practice parsing algorithms you don’t need to create a new programming language like I did. In fact, you don’t even need to build a full Compiler. There are open source projects that let you focus on the Parser only. You may find some on GitHub.
That said, the whole process of creating a new programming language is, in my opinion, extremely beneficial. In particular, the variety of algorithms, data structures and design patterns make some great pieces of knowledge for every serious computer scientist.
References
My article What Is a Programming Language Parser?.
My article How to design a programming language parser.
My article Design of a New Context-Free Grammar.
My GitHub repository for this course.
Alex Aiken’s class Compilers at Stanford University. Available as free MOOC online.